大規模言語モデル(LLM)のさらなる活用を目指して:データ前処理とFine-tuning

はじめに
株式会社cross-Xの古嶋です。DX戦略の立案やデータ・AI活用の支援をしています。
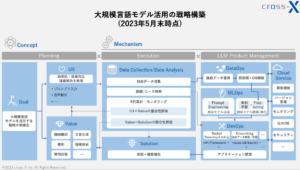
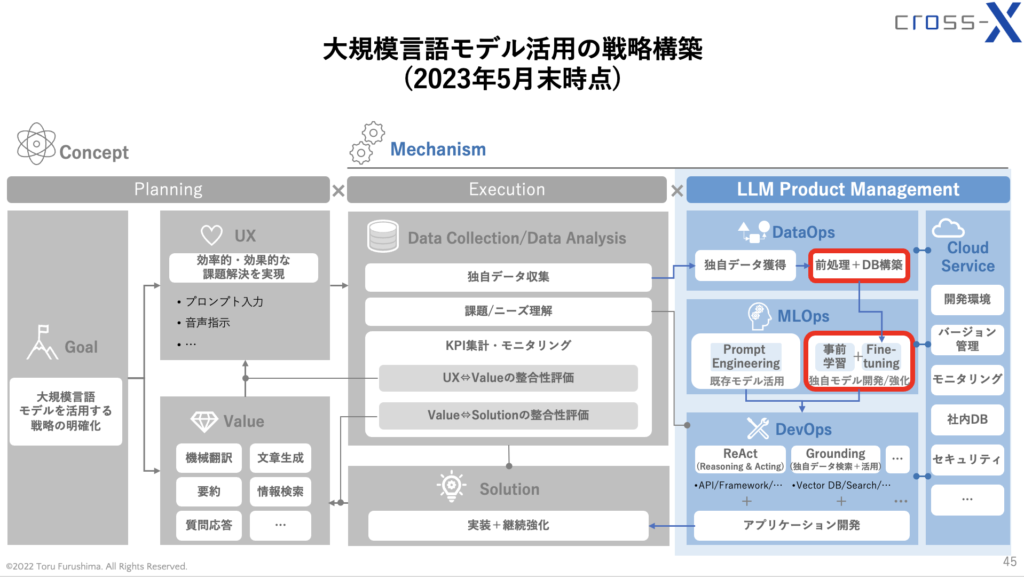
今回は、大規模言語モデル(LLM: Large Language Model)活用が進むに連れて論点となりやすい「学習用データの前処理」及び「開発済みLLMのFine-tuning」について、その手法に焦点を当てて解説します。弊社が提唱する大規模言語モデル(LLM)を活用するための戦略・実務フレームワーク(下図)の赤枠部分に該当します。
ChatGPTを実務で活用する企業が日々増えています。そんな中で、例えば「出力が遅い」という悩みを伺うことが増えてきました。GPT-4をベースとした場合、Promptによる対話やGroundingの実行による出力精度は高いものの、どうしてもスピードが落ちる傾向が見受けられます。この点、LLMの処理速度を高めるには、例えば以下の2つの観点があると思われます。
- 事前学習の段階から、LLMの利用目的に特化したデータで学習を行っておく。
- 既存LLMが学習済みの出力精度や能力を活かしつつ、Fine-tuningによって少ない入力トークン数でも特定ドメインのタスク処理に適した出力を得られるようにする。
他にもサーバー強化や量子化による計算負荷の削減、GPT-3.5などの旧モデルを採用するといった手法もありますが、本記事では上記2点に絞って解説します。
1.について、本記事では事前学習に必要となるデータ前処理について概観します。次いで、2.についてはFine-tuningの概観及び各種手法について解説します。
事前学習
LLMにおいて事前学習とは、非常に簡単に言えば、大量の文章を学習して語彙や文法、文章表現などのパターンをLLMに理解させるプロセスを指します。以前の記事「ChatGPTの出力が毎回変わってしまう理由:確率モデルの考察と、出力を安定させる方法」で、以下のようなLLMの確率的な振る舞いを示しました。厳密には、例えばGPTシリーズではTransformerのDecoderを用いて単語を出力するため、画像のような条件付き確率ほど単純な構造ではないのですが、「既出の単語に基づいて次の単語を確率的な観点から出力する」という点では条件付き確率と共通すると考えられます。
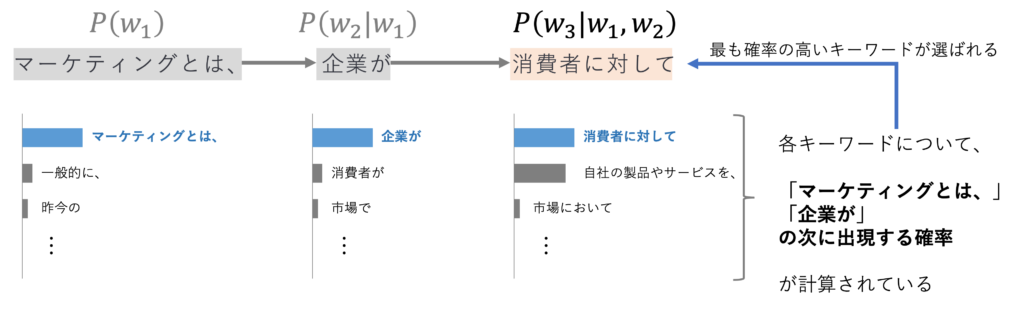
このように、「どのような単語を出力すればよいのか」を計算・実行する処理を繰り返すことで、LLMはテキストを生成します。このときの出力する単語がより適切なものになるように、大量のデータを学習させるものだ、と考えておけば良いと思います。
すると、当然ながら「雑な言葉遣い」であったり、そもそも事実として「間違っている説明」を含む文章をテキストデータとしてLLMに学習させると、そのLLMが出力する文章の精度が低くなる可能性が高まります。よって、事前学習においては学習させるテキストデータの量だけでなく、質が極めて重要です。
そこで、以下にテキストデータの前処理について簡単に整理します。
学習用データの収集
まずは、そもそも学習させるテキストの元となるデータを集めます。このデータによって、LLMがどのようなタスクに対応出来るのかが決まるといっても良いと思います。以下の画像はA Survey of Large Language Modelsに掲載されている画像ですが、ご覧の通り、各LLMによって学習されているデータに特徴が見られます。
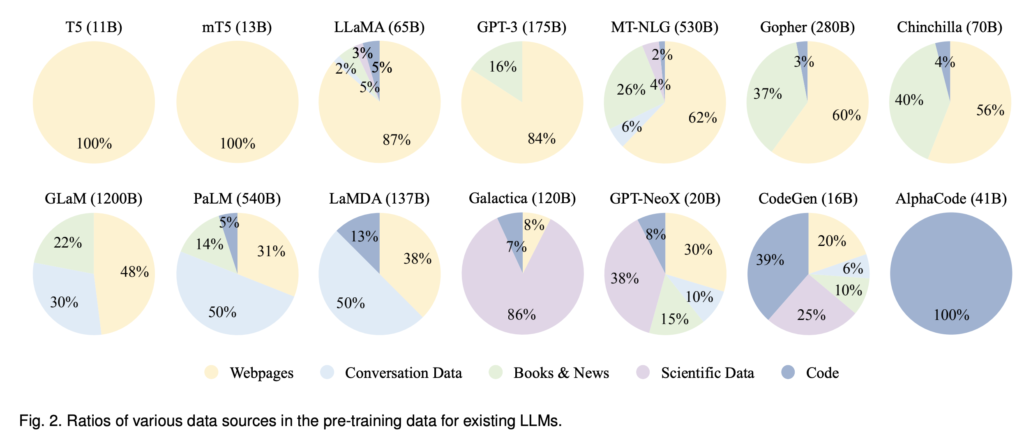
以下、代表的なデータセットを簡単に記載します。
BookCorpus
GPTモデルやBERTなどで初期的に用いられているデータセットです。幅広い話題やジャンルをカバーする11000以上の書籍から構成され、トロント大学とMITの研究者による2015年の論文「Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Read Books」で紹介されました。
電子図書館として、小説、エッセイ、詩、ドラマ、歴史、科学、哲学、その他パブリックドメインの作品を含む7万冊以上の文学書を包含しています。
ペタバイト級のデータ量を持つ、オープンソースの最大級のウェブクローリングデータベースです。既存のLLMの学習データとして広く利用されています。ただし、ウェブデータにはノイズや低品質な情報が広く存在するため、利用前にデータの前処理を行う必要があります。

ユーザーがリンクやテキストを投稿することができるソーシャルメディアプラットフォーム。「upvote」や「downvote」で他のユーザーが投票可能です。 upvoteされた投稿を高品質のデータセットだと見なし、活用することができます。
ウィキペディア
言わずと知れたオンライン百科事典。説明的な文体で構成されており、幅広い言語や分野をカバー。Wikipediaの英語記事は、多くのLLMで利用されています。
不要なデータの削除
学習用に収集したデータの中から、不要なデータや低品質なデータを除去します。アプローチの手法としては、分類器を用いるケースと、ヒューリスティック(発見的)に不要なデータを特定して削除する場合があります。
分類器を用いる場合、例えばWikipediaなどで訓練したアルゴリズムを分類器として採用し、各テキストデータを読み込んで不要なデータを特定、除去します。
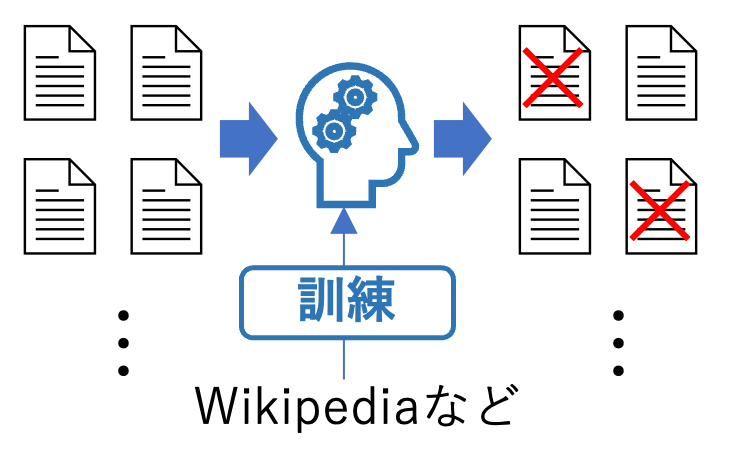
ただし、この手法だと本当は必要なデータを削除してしまうリスクがあるため、ヒューリスティックな手法も採用されます。例えば以下のような手法が挙げられます。
- 特定の言語以外の言語のテキストを検出・除去
- 評価指標(perplexity等)を用いて不自然な文章を検出・除去
- コーパスの統計的特徴(句読点分布/記号と単語の比率/文の長さ等)に基づきテキスト品質を測定
- HTMLタグ/ハイパーリンク/定型文/不快な言葉などノイズや不用な要素を特定・削除
重複データの削除
重複しているデータが存在すると学習後のLLMの精度に影響するため、重複データは削除します。大きく以下の3つの観点で行います。
文レベル:
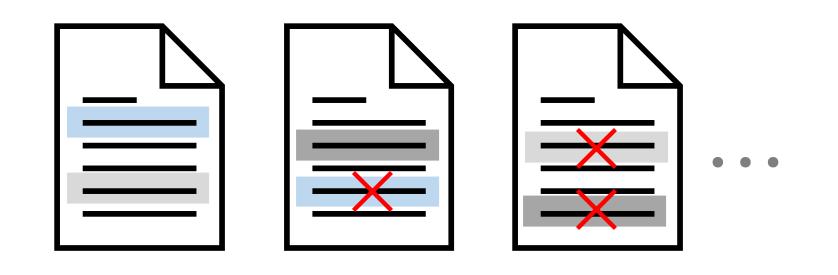
繰り返される単語やフレーズを含む低品質な文を除去
文書レベル:

文書間の特徴の重複率に基づき、類似内容を含む重複文書を検出・除去
データセットレベル:
訓練データと評価データの間で重複を防ぐ
プライバシーデータの削除
個人情報等のプライバシーデータや機密性の高いデータが学習データに混在している場合、プライバシー攻撃に対するLLMの脆弱性に寄与してしまうことが分かっています。
よって、事前学習用データから個人情報や機密データを取り除く作業が不可欠です。例えば、キーワード検出などのルールベースの方法を使用して、氏名や住所、電話番号などのデータを検出して削除します。
テキストデータのトークン化と単語埋め込み
テキストデータは、そのままの形式だと学習可能なデータとして適していません。そこで、テキストデータを細かい単位に分割し、さらに分割した単位ごとに数値化します。この「細かい単位に分割」することをトークン化と呼びます。また、各トークンを数値化することを埋め込み(ベクトル化)と呼びます。
例えば、"I have an apple"という文章をトークン化+埋め込みを行うケースを示すと以下のようになります。[CLS]は文章の開始、[SEP]は文章の終了を示しています。

具体的には、分割したトークンごとにOne-hot ベクトルを作り、埋め込みベクトルを用いて各トークンを多次元のベクトルで表現します。上図で各トークンが複数の値のベクトルに変換されている様子が見られると思います。
この埋め込みを行うためのベクトルは多次元で構成され、各トークンを多次元の数値で表現します。これにより、例えば多義語の観点やトークン間の類似性を解析的に解釈することが可能となります。この埋め込みを行うベクトルは重み(=パラメータ)として扱われ、学習を通じて値を更新していきます。また、この埋め込みベクトルの次元数は、モデル設計者が予め設定します。次元数を数万次元のように大きくすれば、各単語をより多角的に捉えることが可能になる一方、計算量の増大などの課題も生じます。
Fine-tuning
学習用データの前処理を完了させ、前処理後のデータをLLMに学習させると、LLMは一定の言語や文法を理解したモデルとなります。このLLMの精度をより高めたり、特定のタスクに特化したモデルへと改良するための手法としてFine-tuningが採用されます。

Fine-tuningの必要性と効果を簡単に整理すると下図の通りです。
必要性:
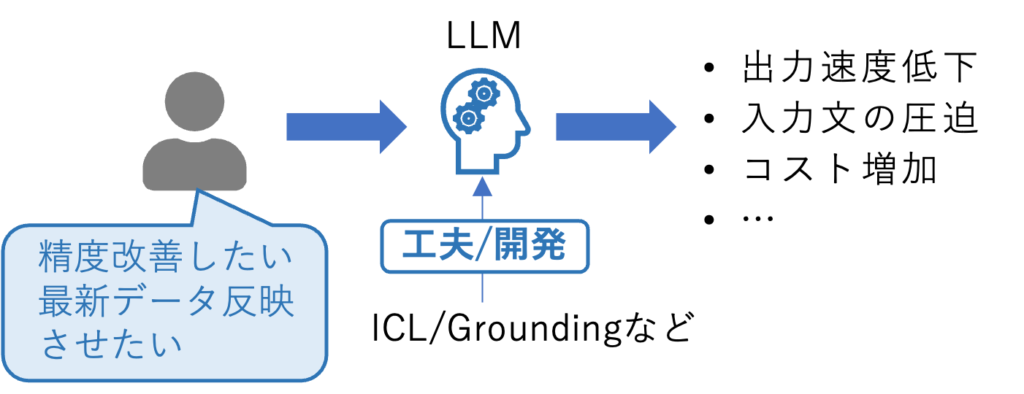
既存LLMを維持しながら回答精度向上や最新データ対応を図ると、入力トークン数増加等で情報処理量が膨らみ、通信速度の低下やコスト増などの問題が生じる
効果:
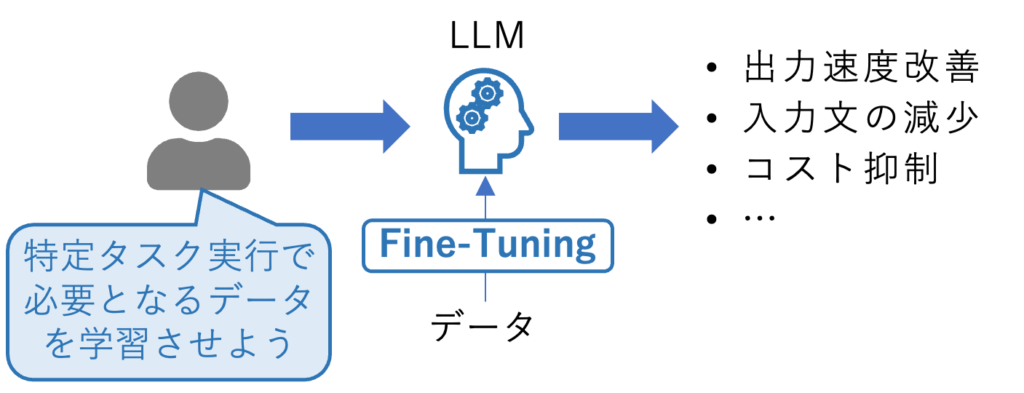
精度向上に必要なトークン数が減り、情報処理の速度向上と精度向上、さらにはデータ量削減を狙える(ただし、実運用を通じて要検証)
Fine-tuningにはいくつかの実行パターンがあります。この記事では以下の3つの手法について簡単に解説します。
- 一般的なFine-tuning:モデル内に存在するすべてのパラメータを対象としてFine-tuningを実行
- 強化学習を取り入れたFine-tuning:RLHF(Reinforcement Learning from Human Feedback)を実行
- 部分的なFine-tuning:モデル内に存在するパラメータを固定しつつ、追加的にパラメータを付与して、そのパラメータのみを学習対象として実行
一般的なFine-tuning
ここでは、TransformerのEncoder部分を例としてFine-tuningについて考察します。TransformerのEncoder部分とは、以下のTransformerのアーキテクチャ全体のうち、左半分を指します。図は、Attention Is All You Needより抜粋しています。
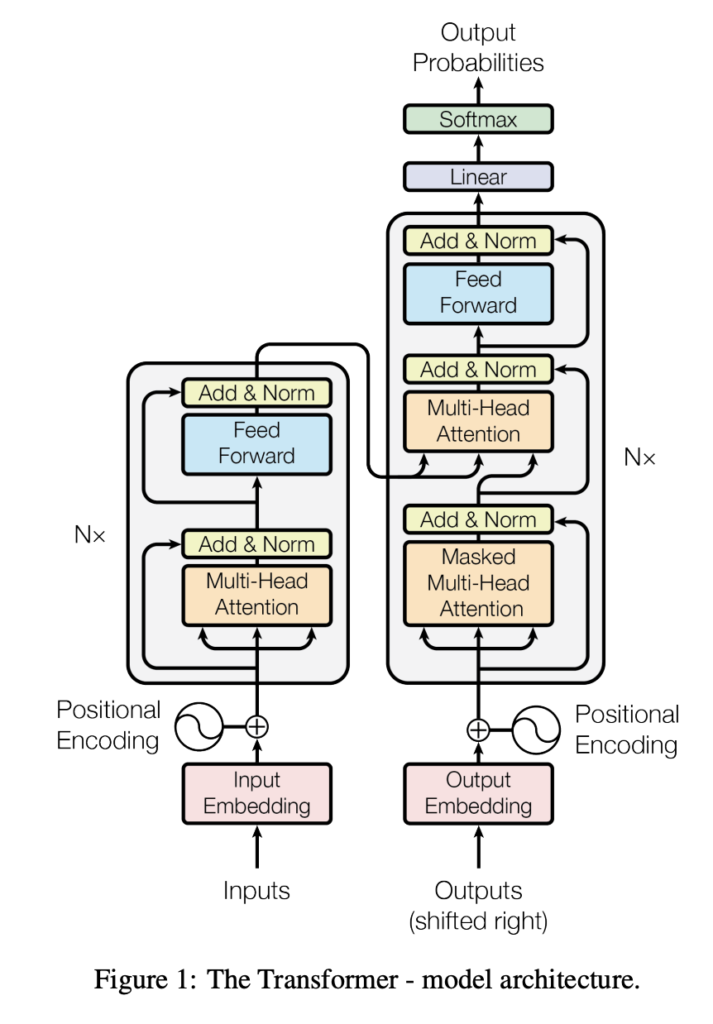
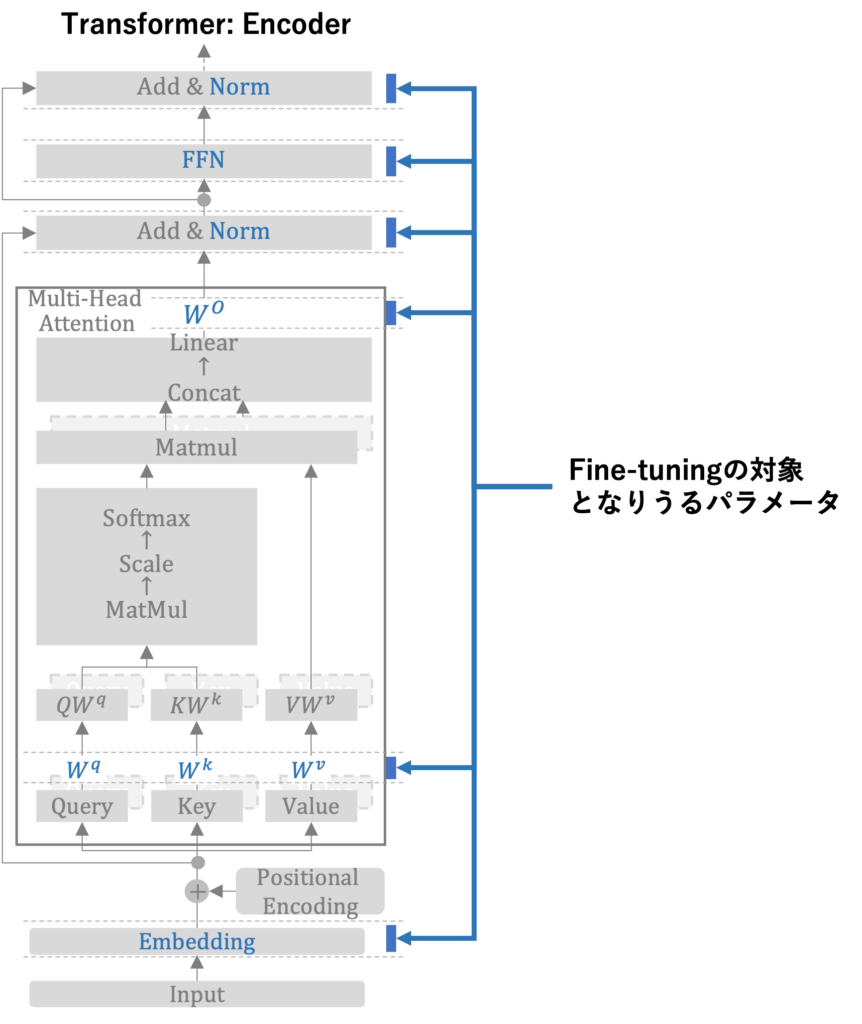
この左半分をより詳細に分解すると下図のようになります。ここでは詳細には立ち入りませんが、示したい点として、Fine-tuningが対象とするパラメータ数は非常に多く、かつアーキテクチャ内のさまざまなポイントで存在しています。よって、Fine-tuningを実行するためには多くの労力とマシンリソースが必要となります。
ちなみに、昨今はTransformerについての解説記事や動画が非常に充実しており、理解の大きな助けとなります。個人的に推奨するのは以下のYoutube動画です。英語による解説であることと、解説に若干の誤りがある(コメント欄に誤りへの指摘が入っているので、それらを加味しながら動画を閲覧すれば問題なさそうです)という点もありますが、仕組みを理解するうえでは非常に良い内容です。Transformerは動的な振る舞いを示すので、静止状態の図よりも、データや計算の流れを動的な表現をもとに解説してくれるコンテンツが解説には適していると個人的に思います。
RLHF(Reinforcement Learning from Human Feedback)
Fine-tuningを実行する際、より人間の嗜好性や考え方、価値観などを明確にLLMに学習させたいというニーズがあります。現在世界を席巻しているChatGPTについて、その根幹となっている言語モデルのGPT-4は、RLHF(Reinforcement Learning from Human Feedback)を行ったことでその性能を実現しています。
RLHFは大きく以下の3つのステップで行います。詳細は、学習データの節でも紹介したA Survey of Large Language Modelsに大変分かりやすく書かれています。
Step1: 教師ありデータによるFine-tuning
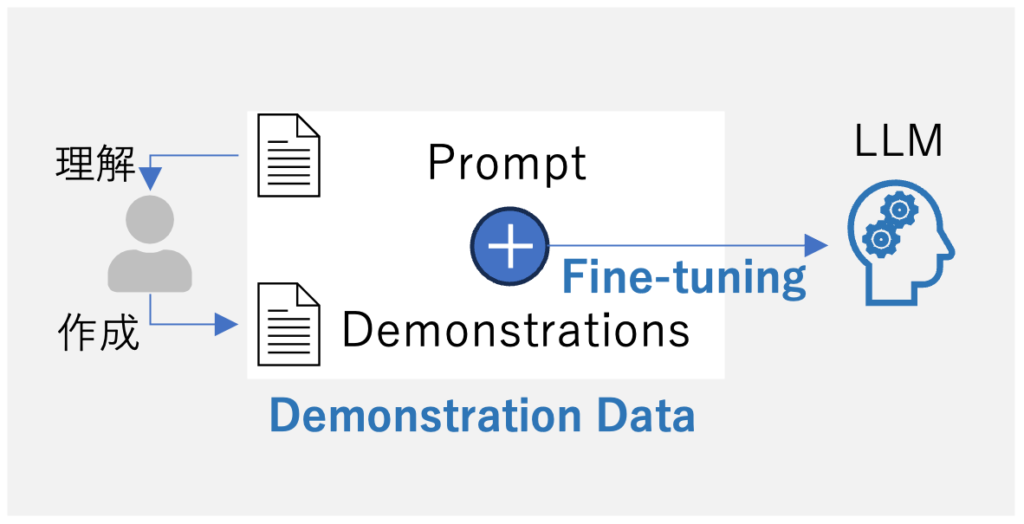
LLMをFine-tuningするための入力プロンプトと望ましい出力(デモンストレーション)を含む教師付きデータセットを収集。デモンストレーションは人間のラベラーが作成する。
Step2: 報酬モデル(Reward Model)のトレーニング
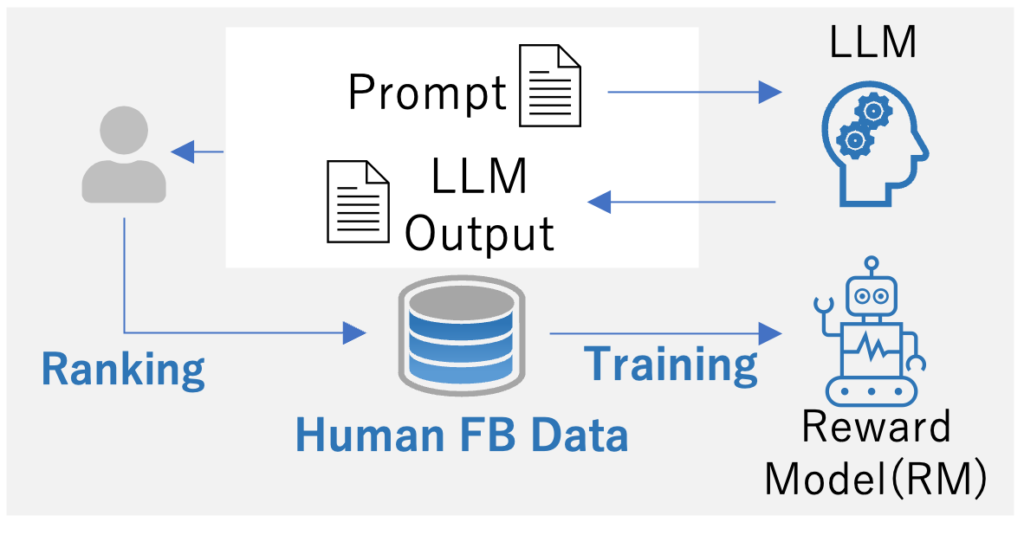
教師ありデータセットまたは人間が作成したプロンプトを入力として使用し、一定数の出力テキストをLLMが生成。生成された出力に対して人間のラベラーが入出力ペアの嗜好をアノテーションすることで、RMは人間が好む出力を予測するように学習される。
Step3: 強化学習(RL)によるFine-tuning
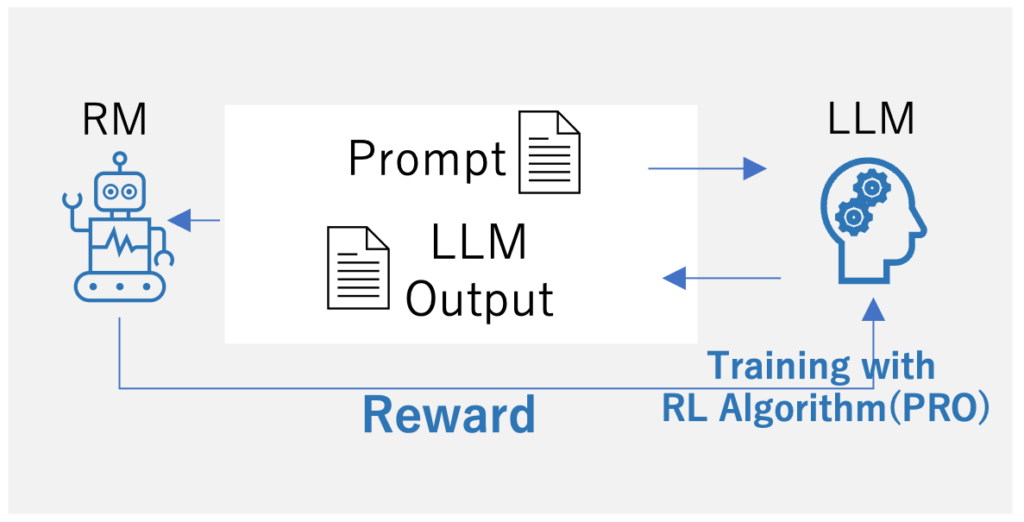
LLMのFine-tuningを強化学習の問題として定式化。具体的には、事前訓練されたLLMはプロンプトを入力として出力テキストを返す“ポリシー”として機能。行動空間は語彙、状態は現在生成されているトークン列、報酬はRMによって提供される。
PEFT(Parameter-Efficient Fine-Tuning)
Fine-tuningを実際に行う際、いくつかの課題やリスクがあります。特に大きなポイントとしては、「実行・運用における負担」と「LLM性能劣化のリスク」があります。
- 実行・運用における負担:LLMのパラメータ数が多くなるほど、Fine-tuningで調整するパラメータ数が多いことになる。すると、学習に必要となる計算コストや、変更前後のパラメータを保存するるためのコストなどが増加する。さらに、タスクごとにFine-tuningを行うと、全パラメータをチューニングしたLLMを複数保持することになり、膨大なコストがかかる。
- LLM性能劣化のリスク:Fine-tuning用のデータに過学習してしまうと、従来持っていた出力精度を毀損する恐れがある。さらには、事前学習で獲得していた知識やタスク処理能力を失う可能性もある。
このような問題を回避するために、事前学習によって学習されているパラメータを変更することなしに、追加的なパラメータを置き、そのパラメータのみを追加データで学習させるという手法があります。このような手法を総称してPEFT(Parameter-Efficient Fine-Tuning)と呼びます。本記事では、PEFTの手法としてAdapter、Prefix-tuning、LoRA(Low-Rank Adaptation)について簡単に解説します。
TransformerのEncoder部分を例にとると、Adapter、Prefix-tuning、LoRAはそれぞれ下図の部分に主に適用されます。
参考: TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING
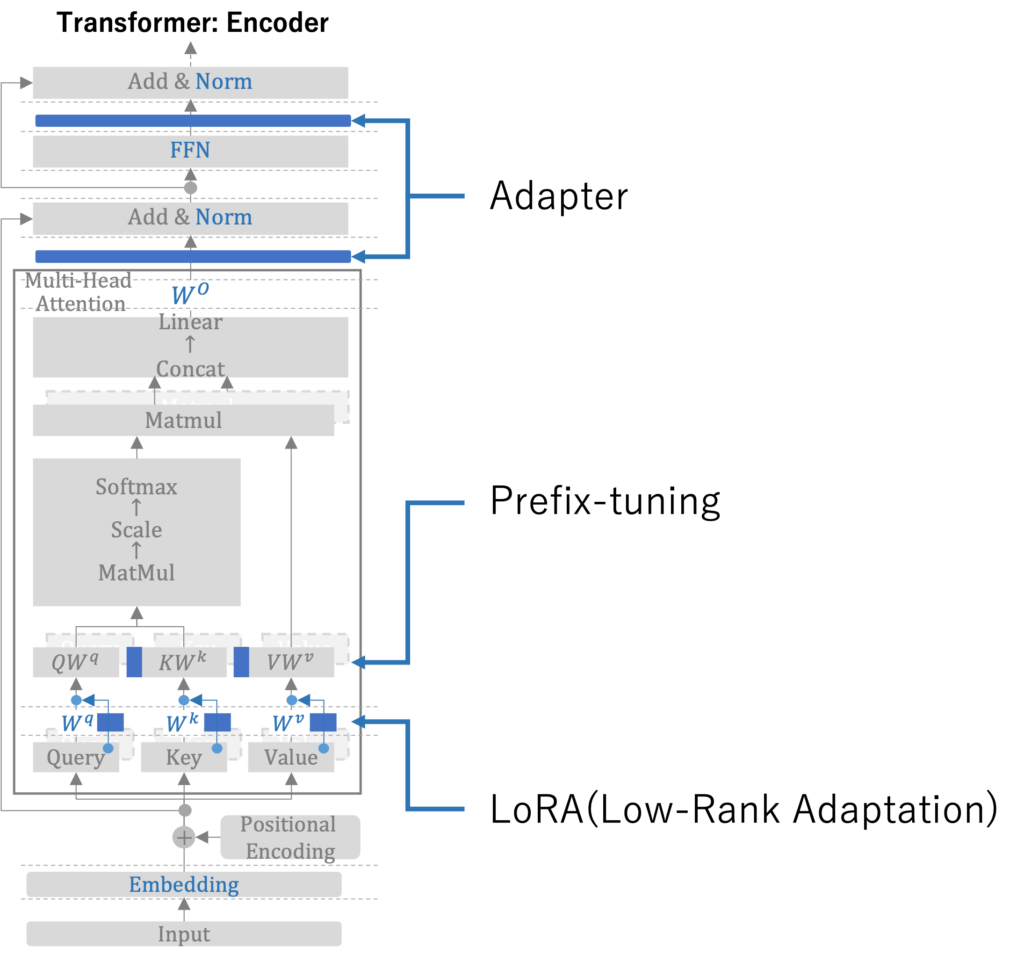
それぞれの手法の概念図と簡単な解説を記載します。
Adapter:
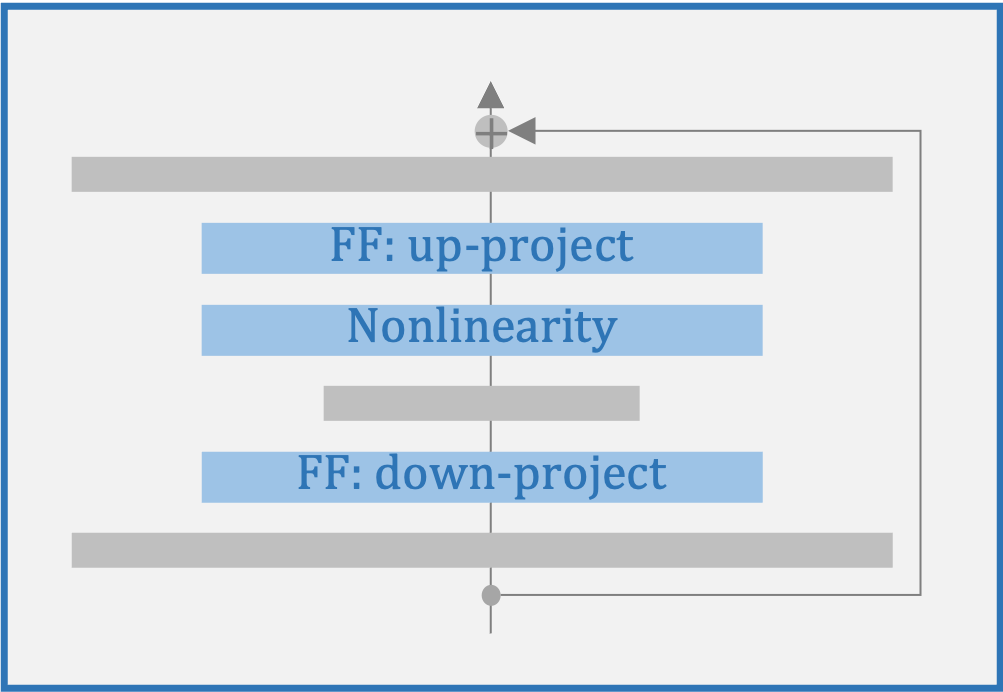
他のパラメータを固定しながら、Adapter内のパラメータのみを学習させる。非線形変換による処理を行って精度向上を目指す点に特徴がある。ただし、モデルに直列的な実装を行うため、並列計算処理のメリットを享受することが難しい。
Prefix-tuning:
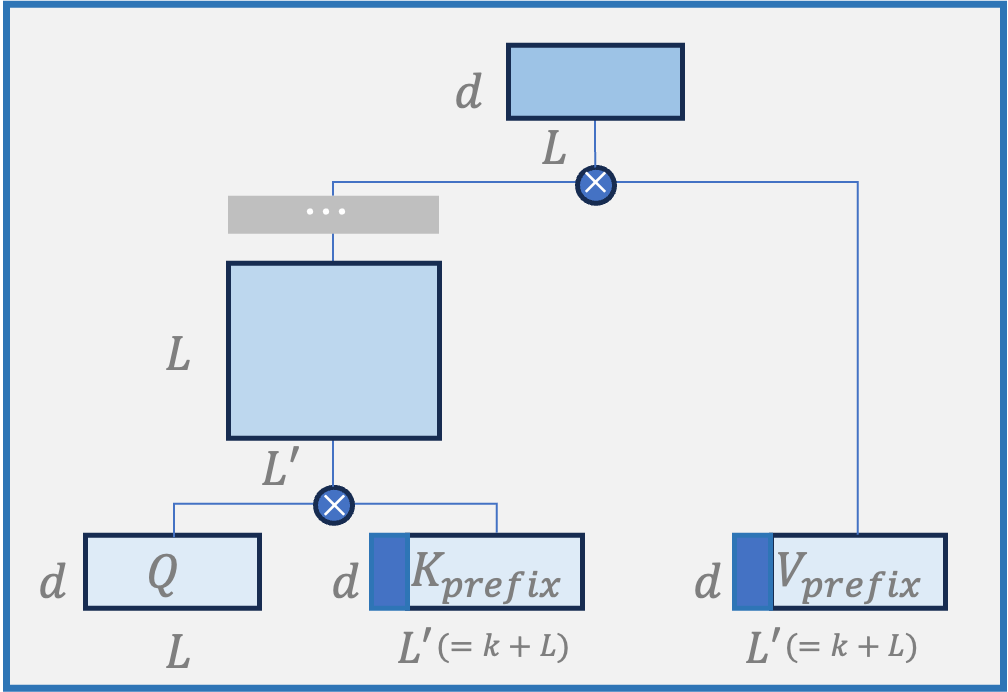
Attention層で重みづけたK, Vの先頭にタスク固有のPrefixを追加し、他のパラメータを固定しながらPrefixのパラメータのみを学習させる。タスクごとにPrefixを用意し、それぞれのパラメータを学習・保存する。
LoRA:
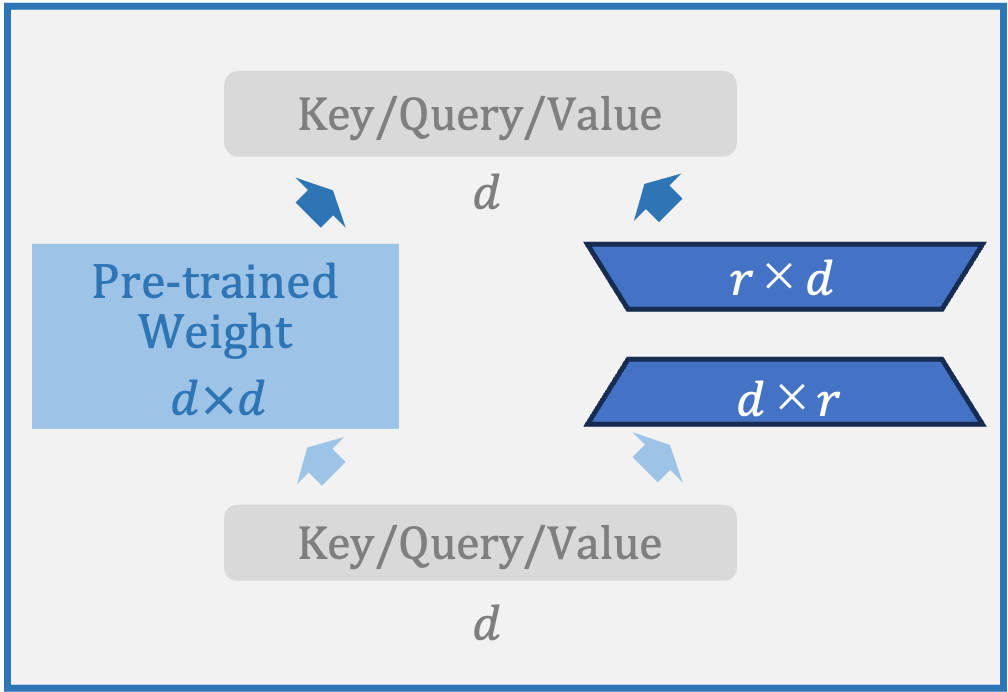
Attention層でQ、K、Vに重み付けるパラメータに低ランク行列を並置し、他のパラメータを固定しながらこの低ランク行列のパラメータのみを学習させる。線形変換処理で計算量を抑制しつつ、タスクごとに低ランク行列を用意して学習させることが可能。
終わりに
今回はLLMに関連する主要な技術として、事前学習とFine-tuningに焦点を絞って解説しました。現在の各社の取り組みとしては、既存のLLMを有効活用するための手法が模索されている段階が主だと見受けられますが、活用レベルが高まってくるとそもそもLLM自体を独自に開発したり、開発済みのLLMの精度向上を目指したFine-tuningに着手する企業も現れてくると思います。そういった際の考察の糸口として、本記事が少しでもお役に立てれ嬉しく思います。
最後までお読み頂き、ありがとうございました。皆さまの実務において、何かしらのヒントになれば幸いです。