
ChatGPTの出力が毎回変わってしまう理由:確率モデルの考察と、出力を安定させる方法

はじめに
株式会社cross-Xの古嶋です。DX戦略の立案やデータ・AI活用の支援をしています。
ChatGPTを使っていると、同様の質問内容に対して毎回の回答結果が異なるという現象に出くわしたことがある方は、今となっては少なくないと思います。この点、実務でChatGPTなどの大規模言語モデル(LLM)を活用するとなると、毎回の出力結果が異なれば、実務において問題となりうるケースも出てくるのではないでしょうか?しかし、この点はその根拠と対応策を知っておけば、十分に対処可能です。
そこで、今回は、大規模言語モデルの根幹となる確率的言語モデルについて解説します。そして、毎回の出力結果が異なる理由、及びOpenAI APIを利用した場合の出力内容を安定させる方法を示します。
まずは以下を御覧ください。これは、「マーケティングとは何ですか?」という質問をChatGPTに2回行ったところ、出力内容が双方で異なっている様子を示しています。
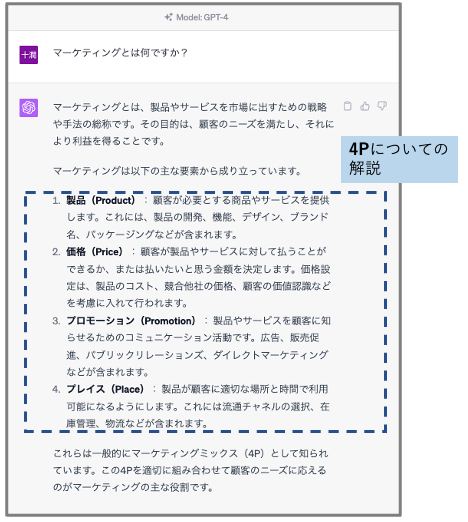
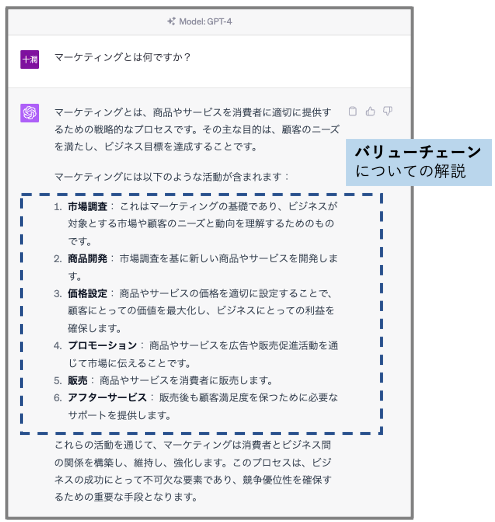
1つ目の回答はいわゆるマーケティングフレームワークの4P(Product/Price/Place/Promotion)についての解説がされています。一方、2つ目の回答はマーケティングの実務におけるバリューチェーン、あるいは実務のプロセスのような内容が解説されています。
どちらの回答も決して間違っておらず、妥当な内容ですが、そもそもなぜ、このような回答の「違い」が生まれるのでしょうか?本記事では、この点に迫っていきます。
Playgroundで実験
OpenAIのサービスにPlaygroundというサービスがあり、そこでパラメータを変動させることで出力結果を操作することができます。実際に見た方が早いので、まずは以下をご覧ください。ここでも、「マーケティングとは何ですか?」という質問を2回実行しています。
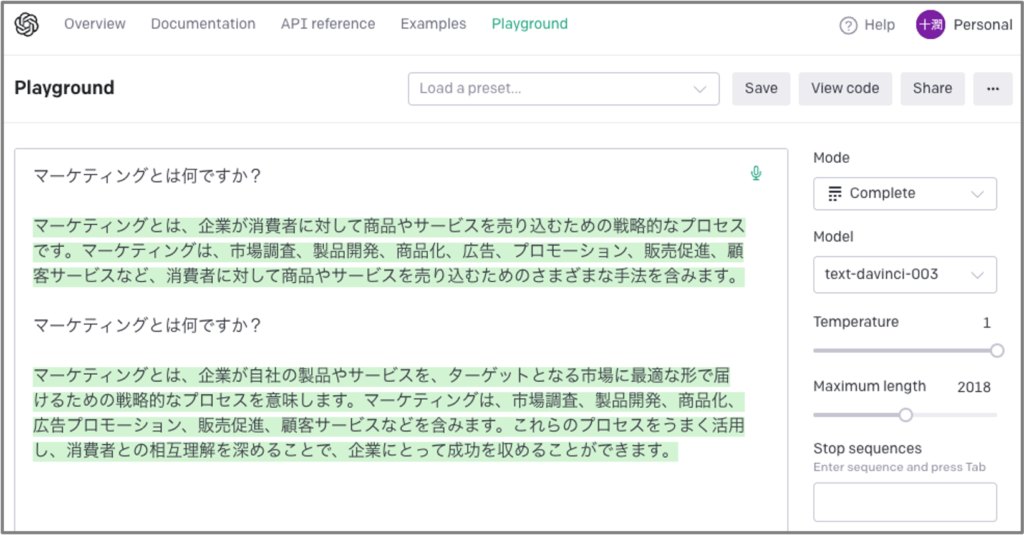
ご覧の通り、ここでも、2通りの異なる回答が出力されています。この出力内容を同じにするには、図の右側にある“Temperature"というパラメータを0にすれば良いです。実際に調整すると出力が下記のようになります。
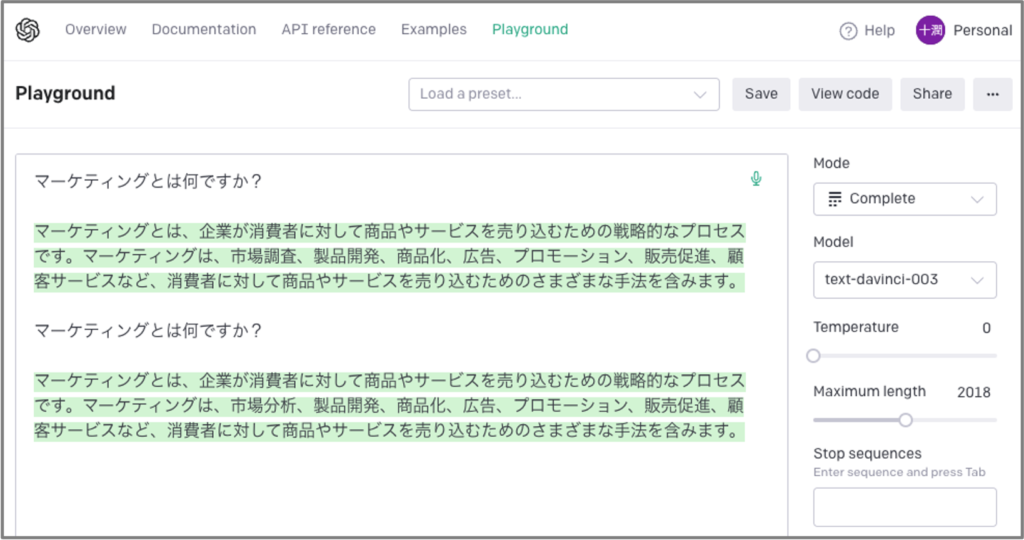
よく見比べなければ気が付かないほど、回答文に相違点が見られなくなりました。
確率的言語モデル
さて、なぜこのようなことが起こるのでしょうか?それは、大規模言語モデルが出力する文章は、確率的言語モデルによって生成されているからです。確率というからには、これは数理モデルとも呼べるものです。よって、少し数理的な視点に踏み込んで考察してみましょう。
以降の解説における注意事項:
尚、厳密な数理的解説に踏み込むと非常に複雑なので、詳しくは専門書などを御覧ください。あくまで確率的言語モデルの“勘所“が掴める程度の理解を目指すものです。
また、以降の解説では単位ごとの単語を“大きく”捉えて、キーワードと称して解説しています。本来、自然言語処理の観点からすると厳密にはもっと細かい単位で単語を考察するのですが、理解のしやすさを優先し、本記事ではある程度のまとまりごとに“単語”を捉えて考察していきます。何卒ご容赦ください。
キーワードごとの出現確率
まず、生成される最初のキーワードが確率的に決まります。質問文に対して回答文を生成する際、その書き始めとなるキーワードとして「マーケティングとは、」というキーワードの出現確率が最も大きい場合、「マーケティングとは、」が最初に出力されます。図解すると下図の通りです。
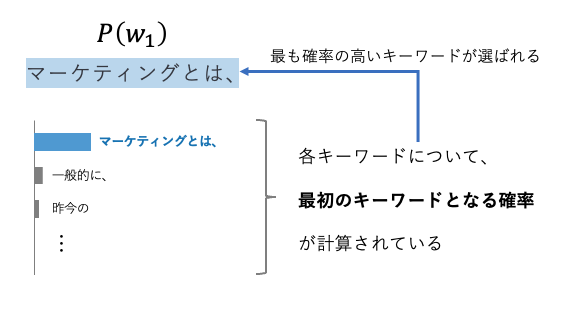
もちろん、「一般的に、」「昨今の」といった書き始めのパターンもあり得ますが、大規模言語モデルがデータを学習した結果、「マーケティングとは、」というキーワードが文章の最初に出現する確率が最も高くなっていた、ということです。ちなみに、この1番目のキーワードを\(w_1 \)と表現し、これが出現する確率を\(P(w_1)\)と表現しています。
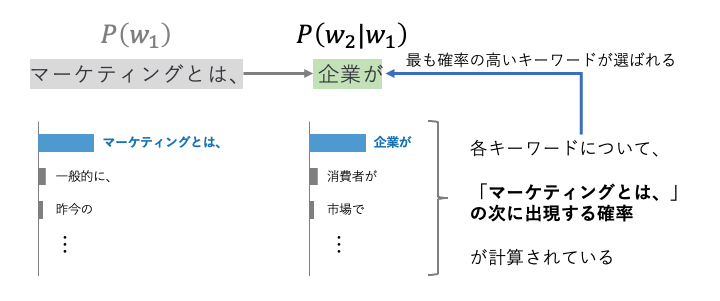
続いて、「マーケティングとは、」に続くキーワードが出力されます。ここでは「企業が」というキーワードが出力されています。これも確率に従って生成されています。もちろん、他にも「消費者が」「市場で」といったキーワードが次のキーワードとして出現する可能性もあるでしょう。しかし、ここでは「企業が」というキーワードが最も出現する確率が高かったということです。
この点についての確率を表現します。先程とは異なり、1つ目のキーワード「マーケティングとは、」に続いて出現する確率が最も高いキーワードが「企業が」なので、2番目のキーワードを\(w_2 \)と表現すると、先程の確率\(P(w_1) \)が起こったあとに起こる条件付き確率となり、\(P(w_2|w_1) \)と表記されます。図解すると下図の通りです。
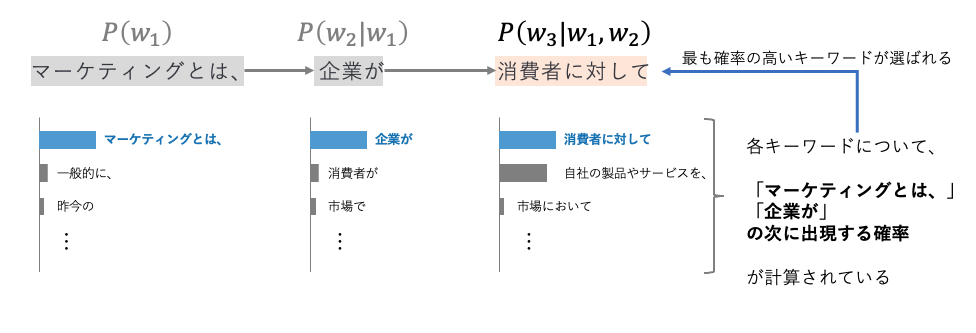
続いて見ていきましょう。次に出現しているキーワードは「消費者に対して」です。ここまでの解説の流れを踏まえると、以下の図をご覧頂ければ意図を掴めると思います。つまり、3番目のキーワードの出現確率は、それ以前の1番目、2番目のキーワードの出現を踏まえた確率だということです。そのため、3番目のキーワードの出現確率は\(P(w_3|w_1,w_2) \)と表記されます。
文章が生成される確率
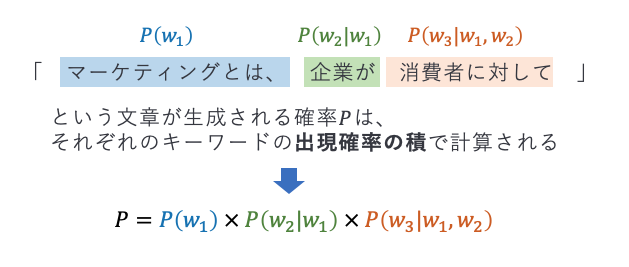
ここまでの確率の表現内容は、キーワードごとの出現確率を表現しているものでした。では、文章全体の出現確率は、どのように計算されるでしょうか?これは、キーワードごとの出現確率の積、つまり掛け算で計算します。この確率を同時確率とも呼びます。例えば、「マーケティングとは、企業が消費者に対して」という文章が生成される確率は、\(P = P(w_1) × P(w_2|w_1) × P(w_3|w_1,w_2) \)と表記されます。
以上を踏まえると、生成された以下の文章について、仮にこの文章のキーワード数が20個だとすると、この文章が生成される確率は以下のようになります。

最後の式変形\(P = \prod_{i=1}^{20}P(w_i|w_{<i}) \)はおまけで書いている程度なので、無視して頂いて大丈夫です。ちなみに、\( \prod \)は総乗を表します。
出力結果が変わる理由
ここまでの内容を踏まえると、先程例示した"Temperature = 1"の場合と"Temperature = 0"の場合でなぜ生成される文章が異なるのか、おおよそ見当が付きます。それはつまり、
- "Temperature = 1" : キーワードの出現確率が「やや低いものもランダムに選ぶ」
- "Temperature = 0" : キーワードの出現確率が「最も高いもののみを選ぶ」
という確率的な操作が、結果として文章全体の出力結果を変えているということです。この点、OpenAIによるTemperatureについての明確な回答が見当たりませんが、Playgroundの出力結果からして、おそらく上記の推察は妥当性が高いと言えそうです。この様子を示したのが下図です。
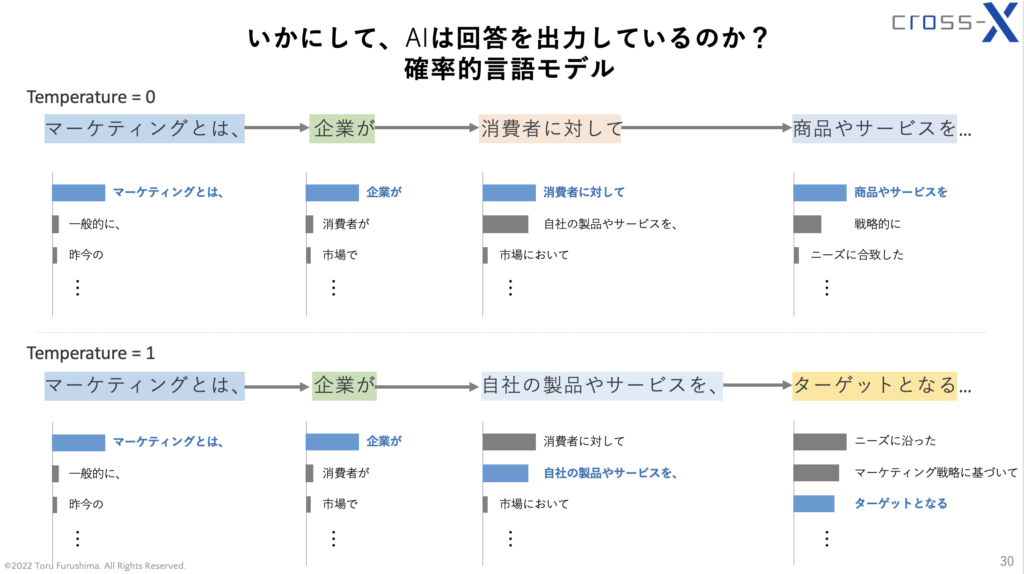
「企業が」に続く3番目のキーワードが、"Temperature = 0"の場合と"Temperature = 1"の場合で変わっています。結果として、4番目のキーワードからは全く異なるキーワードが生成されることになります。図中のキーワード候補はあくまでイメージですが、理解のための表現としてご参考となれば幸いです。
今後、実務においてChatGPTをはじめとした大規模言語モデル(LLM)の活用が増えてくると思いますが、懸念として、毎回の出力結果が異なることに悩む方々が出てくるのではないか?と思っています。その点については、上記の点を理解しておけば、対策が立てられるでしょう。
ちなみに、OpenAI APIをLangChainで操作すれば、Temperatureを0に設定してコードを実行するという処理も可能です。もちろん、逆にTemperatureの値を高めて、敢えて“振れ幅”の大きい出力を得やすくすることも可能です。
数理的補足
参考までに、先程の同時確率を一般化します。生成された文章のキーワード数をNとおくと、総乗記号を用いて\(P = \prod_{i=1}^{N}P(w_i|w_{<i}) \)と表現されます。
この確率モデルを目的関数とし、学習によってこの目的関数を最適化することが、大規模言語モデルの精度に直結します。ただし、このような積算のままでは最適化問題を解くことが困難となるため、一般的には対数を取り、対数尤度関数の形にして最適化問題に取り組みます。対数にする大きなメリットの一つは、総乗記号Πを総和記号Σに置き換えられることです。

以降の詳細は専門書や論文に触れながら理解を深めると、言語モデルの振る舞いを考察する際の取っ掛かりになると思います。LLMはAIの集大成のような産物なので、プログラミングに加えて数理的な観点を養うには格好のテーマと言えるでしょう。
おわりに
本記事では、確率的言語モデルの基礎的な部分に触れながら、ChatGPTの出力について数理的な観点から考察してみました。
実務においては、再現性が重要だとよく言われます。この点、大規模言語モデルの確率的な振る舞いは、ややもすれば実務の支障となることも今後起こってくるのではないかと思います。AIを徹底的に使いこなすには、プログラムコードや数理的な観点も踏まえた取り扱いが、今後より一層重要になってくると思います。そういった取り組みに少しでも貢献出来るよう、引き続き記事を書いていきます。
最後までお読み頂き、ありがとうございました。皆さまの実務において、何かしらのヒントになれば幸いです。

