
大規模言語モデル(LLM)を活用するための戦略・実務フレームワーク
はじめに
株式会社cross-Xの古嶋です。DX戦略の立案やデータ・AI活用の支援をしています。
今回は、本記事の表紙にも掲載している「大規模言語モデル(LLM)活用の戦略・実務フレームワーク」について弊社の見解を簡単に解説したいと思います。
そもそもですが、このフレームワークの前身は、拙著『DXの実務』でDX戦略の全体像を示した以下のフレームワークです。
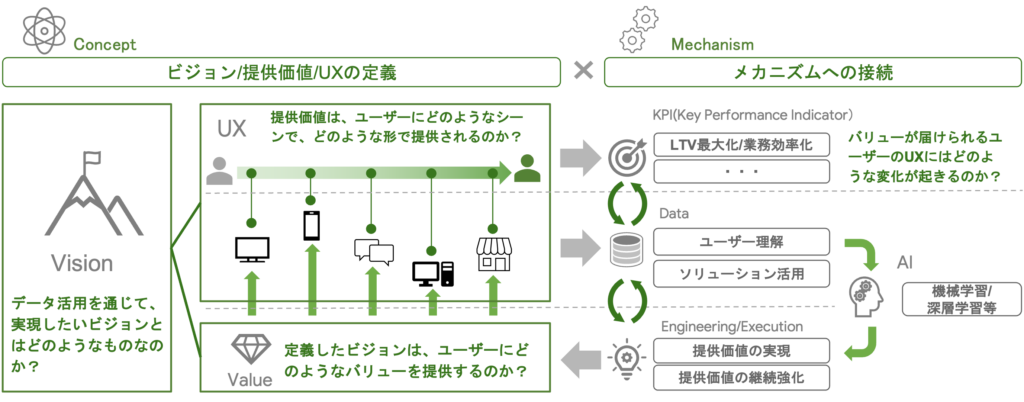
このフレームワークの狙いは「戦略と技術の接続」です。DX、つまりITやAIを活用した戦略及び実務遂行では、ビジネスと開発が分断された状態が相次ぎ、双方に整合性を持たせることが現在も難しい状況です。
この点、主な要因について拙著では3つ挙げていますが、そのうちの1つは「技術的な理解のハードルが極めて高いこと」だと私は主張しています。
戦略と技術が分断した状態を少しでも回避し、DXが前進するために、拙著では様々な観点から方法論を展開しています。特に、上図のフレームワークを用いることで、常に戦略と技術の双方を意識した企画と実務が遂行されることを期待しています。
この点、昨今注目を集めるLLMの活用は、そもそもLLM自体が高度なIT、AI、さらには数理モデルを包含した“叡智の集大成”とも呼べる存在です。ChatGPTのように対話型のUIを通じてプロンプトで操作している分には良いですが、それをよりニーズに応える形で活用するとなると、多岐にわたる知見と技術が求められます。昨今注目を浴びているReAct(Reasoning and Acting)やGroundingといった手法を採用しようとなると、LangChainのようなフレームワーク活用や、ベクトル検索のためのデータベース設計、情報検索に関する知見など、表層的に見ても実に多くの周辺技術が存在しています。
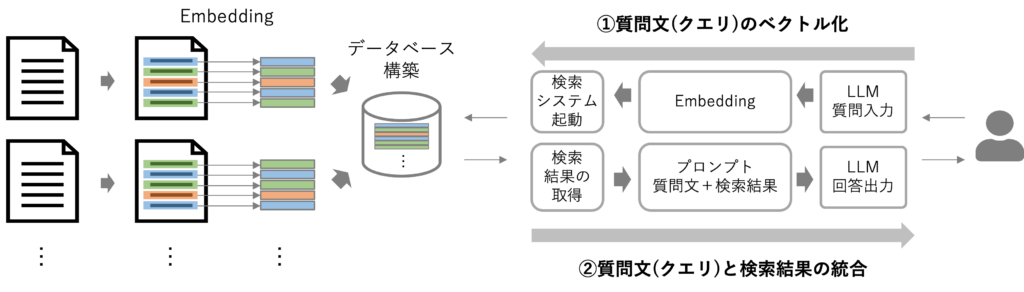
例えば、Groundingのアプローチでは、文章をChunk単位で分割し、検索システムと組み合わせることで必要な情報をLLMに与えつつ回答を出力させることができます。
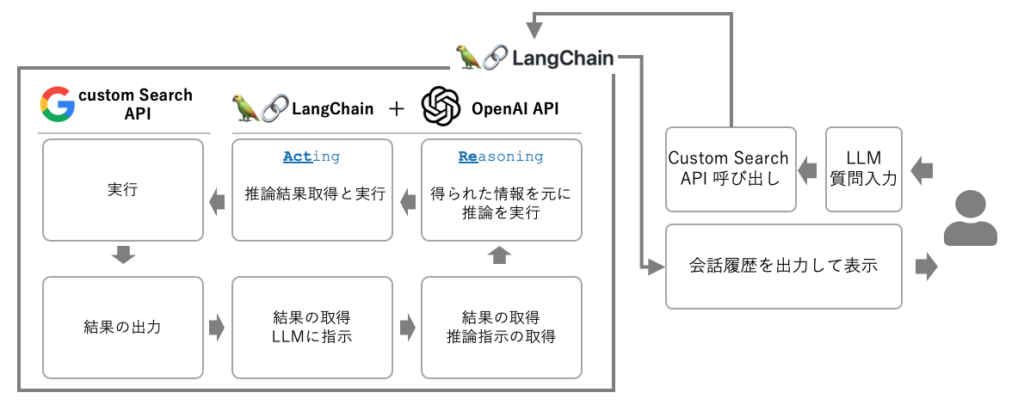
また、ReActのアプローチでは、代表的な手法としてはLangChainを活用してLLMと検索用のAPIを操作して、検索した情報を踏まえた推論を繰り返し、出力精度を高めることができます。
さらに、オープンソースのLLMを活用するとなると、課題解決に資するデータを収集・前処理してFine-tuningを行うことが必須となるでしょう。また、用途に応じてgpt-4とFine-tuningしたLLMを併用した実務推進を行うというパターンもあるでしょう。加えて、開発環境整備やセキュリティ対策が必須となるので、クラウドサービスの活用も多くの場合において欠かせないものとなると思います。
特に重要なのは、「そもそも何のためのLLMを使うのか?」を明確にすることです。私の立場としては、AIのような創発的な取り組みが重要となるテーマでは「とにかくやってみる」というスタンスと行動量の多さが重要だと常々発信していますが、LLMに関しては「何がどこまでできるのか分からない」という雰囲気が色濃い印象を受けます。ですので、そもそも「何ができるのか/できないのか」を知り、その上で「何を狙うのか」を言語化しておくことは極めて重要な準備となると考えています。
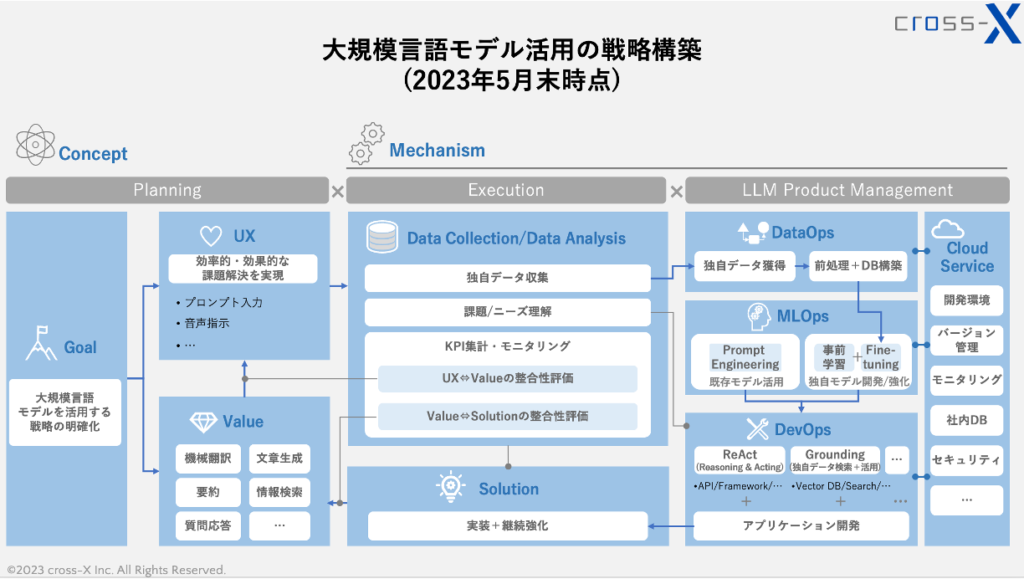
こういった点を鑑み、先程提示したフレームワークを改良したものが以下のフレームワークです。
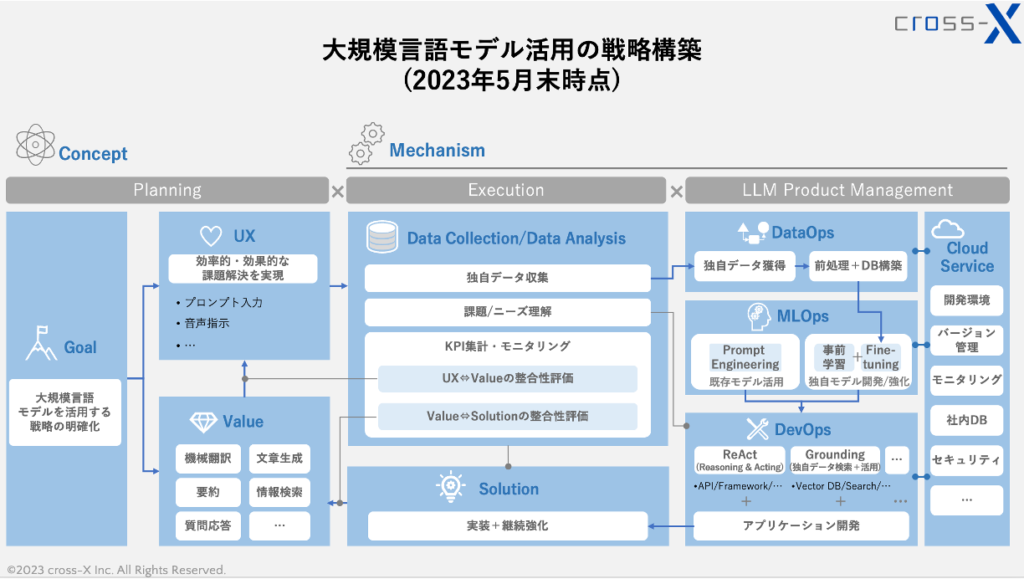
あくまで2023年5月末時点での考察結果であることや、表現できる情報量に限度があるため不十分な可視化となっているところもあるかもしれません。弊社がこれまでLLM関連のプロジェクトや研修プログラムを通じて得た知見を整理したものとしてご参考として頂ければと思います。以下に簡単に解説します。
Planning
Planningのステップでは、そもそも大規模言語モデル活用で目指すGoal(目的)を具体的に言語化する必要があると思います。
この点、言語化の“強弱”が重要で、あまりにもカチッと決めすぎると創発的な取り組みが生まれづらくなります。LLMを活用する実務の範囲を限定してしまうと、課題解決のポテンシャルが弱くなってしまうでしょう。
また、LLM活用によって何ができるのかをある程度整理し、関係者に説明できるようにしておく必要があります。大多数の方々は、LLMで出来ること/出来ないことを区別することが難しい状況にあると見受けられます。そのような中で「とにかく何かやってみよう」と指示だけしても、「一体何をすれば…」と悩む方々も少なくありません。この点、図で示したValue(提供価値)を整理することで、「こういった類のことが出来る」ということを用例とあわせて提示することは、活動のスタート地点として極めて重要な準備です。
さらに、ValueによってUX(ユーザー体験)がどのように変化・改善されているのかを検証し、目的に資する課題解決が実現されているかをしっかりとモニタリングすることが重要です。その際、そもそも「どのようなユーザー体験を実現したいのか」を言語化しておくことが重要です。ただし、この点もGoalと同様、あまりにも目指すべきUXを堅苦しく定めてしまうと、LLMを活用した創発的な取り組みの障壁ともなりかねないので、ここでも“強弱”が重要となるというのが弊社の見解です。
Execution
Executionのステップでは、実際にLLMを利用する中で生成・出力されたデータを回収し、独自のデータとして活用を目指す取り組みが極めて重要です。
ユーザーのプロンプトを集取するだけでなく、出力内容が優れていたプロンプトを特定したり、多くのユーザーが使いがちな入力パターンを発見したりと、ユーザーの入力文を収集するだけでも非常に多くの示唆を得られます。また、優れた入力文と出力文のペアをデータとして集めておくことは、後述するサービス開発のステップでの活用が期待されます。
さらに、入力文の傾向から実務で各担当者が抱えるニーズや悩みを発見したり、提供しているLLMサービスがUX向上に寄与しているのかについて収集したデータを元に考察することで、実務の改善サイクルが生まれます。
LLMではプロンプトに関するアイデア考察が脚光を浴びがちですが、このように収集したプロンプトを「どのような観点で考察するか」によって、課題発見の精度と成果が大幅に変わる印象を受けます。
LLM Product Management
このステップはスペースの都合上、かなり情報を省いた状態となっている点、ご容赦ください。DataOps/MLOps/DevOpsの一つ一つが非常に大きな開発イシューですので、この箱の中だけで表現仕切ることは出来ませんが、特にLLM開発で重要な点に絞って提示しています。
DataOpsの箱では、収集したデータについて、例として前処理→Fine-tuning実行というプロセスを示しています。もちろん、収集したデータをDBに集約し、GroundingのアプローチでChunk単位で活用するといった用途もあるでしょう。また、PoCを通じてどのようなデータがGoal実現の貢献度が高いのかを検証するといった取り組みもあわせて必要となるでしょう。
MLOpsの箱は、LLMそのものの開発/強化や活用方法を模索する様子を示しています。gpt-4のような完成されたモデル(Fine-tuning不可のモデル、とも言えます)のポテンシャルをどのように引き出すかをエンジニアリングの目線から検証したり、オープンソースのLLMをFine-tuningして精度向上度合いを検証したり、場合によっては事前学習から着手するなどのパターンが考えられます。さらには、複数のLLMを併用するというパターンを考察することもあるでしょう。
DevOpsの箱は、LLMが目的に沿ったパフォーマンスを発揮するためのアプローチを示しています。先述したReActやGroundingはまさにその一つで、他にもUIをどのようにするか、どのようなValueを実現したいかなど、さまざまなパターンの中から目的達成への貢献度が高いプロダクトを目指して開発を進めます。
これらの開発を遂行するための環境構築やセキュリティ対応等としては、現状はクラウドサービスを利用することが欠かせないと思われます。
おわりに
LLM活用を戦略的に進めるための一つのアプローチとして、上記のようなフレームワークを整理して解説しました。それぞれを詳細に解説すると書籍1冊分のボリュームになりうる、重厚なテーマだと思われます。それだけ、LLMが包含する領域が広いということでしょう。
LLMに取り組むことは、昨今声高に叫ばれている学び直し・リスキリングという観点で非常に良い切り口だと思います。これほど多くの種類の“筋力”が求められるテーマは、滅多にないように見受けられます。突き詰めるほど奥深い世界ですが、これを分かりやすく、実務活用と成果創出を実現できるまで十分に伝えることを、弊社としては大切にしていきたいと思っております。
最後までお読み頂き、ありがとうございました。皆さまの実務において、何かしらのヒントになれば幸いです。

